
Summer of 2019. I'm joining a large retail organization that is undergoing a digital transformation. The role I've been hired for is a technical leadership role. The project I'm taking over doesn't even have a complete team yet, which means I'll be wearing all sorts of hats until I hire someone and delegate work. You could say, I'm the only "developer" on the team. Also, the code base is already serving users, and the services are part of a lead generation funnel for one of the grocery networks. So if something goes down, the company loses potential customers and revenue. The fact that the project was developed by an outsourced team that has already left without handing over proper documentation makes things more complicated and fragile.
In a few days, I try to understand how the services are run in production, write missing README and system design papers, and create initial tasks for maintenance. All goes well, and I manage to deploy some changes to the backend. It's Friday afternoon, so I still have time to do a rollback if I've made a mistake. But nothing suspicious has been observed during the day, and I leave the office for the weekend.
The fun begins on Sunday. Because I'm in charge of the project, I'm the one who is on-call. I get a call from our support team telling me that the web application isn't responding from time to time and that they're getting complaints from customers.
The first thing I do is open my browser to check what users are seeing. Surprisingly, a web page loads just fine. I hit refresh – same result. Then I turn off Wi-Fi on my iPhone and open Safari – 504 error. It's a Nginx page. Now it is something.
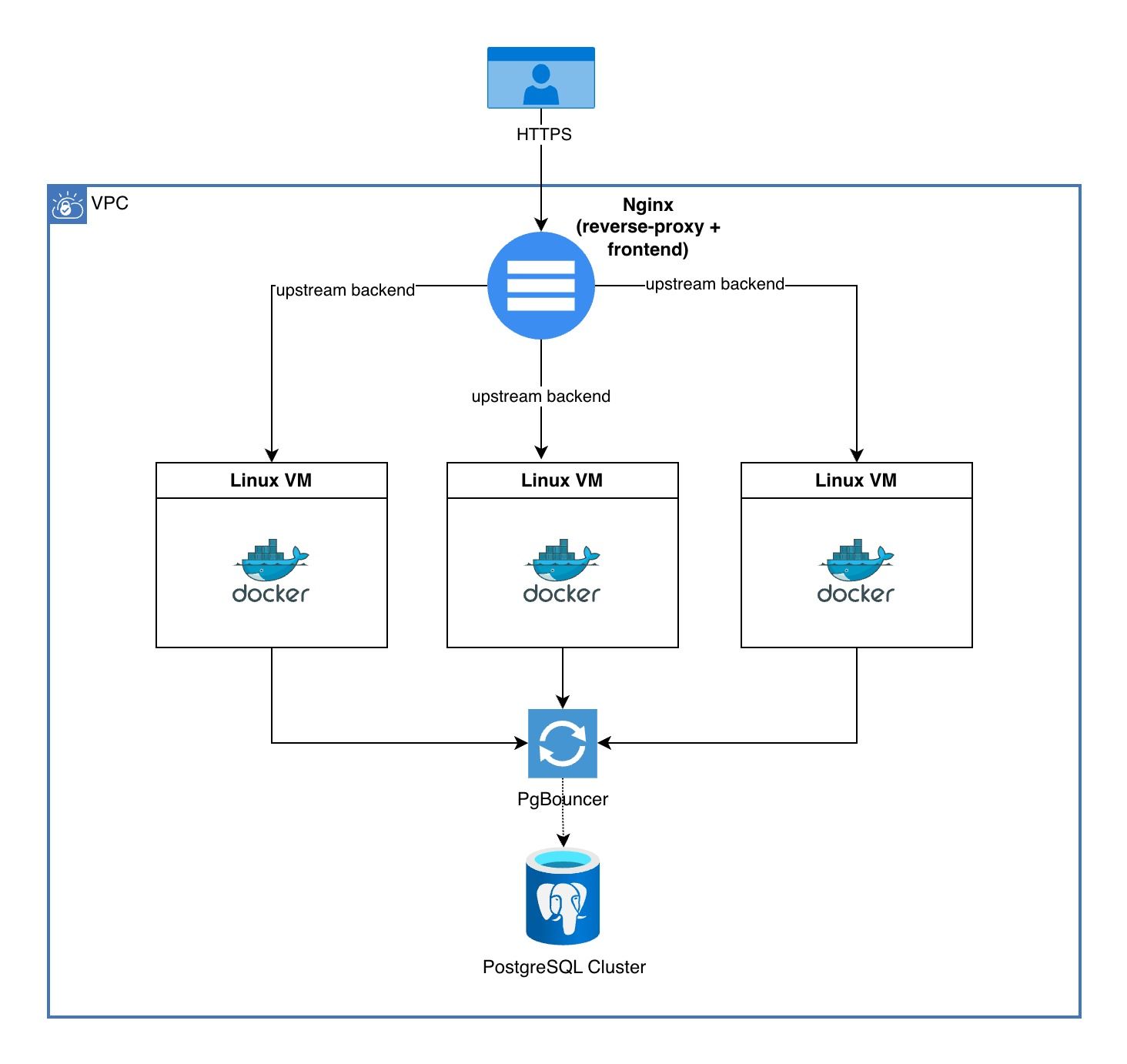 Simplified diagram of the project architecture
Simplified diagram of the project architecture
I open the monitoring and observe no high load. CPU usage is low, more than 50% of memory is free, plenty of free disk space on each of the virtual machines, no spikes in the network bandwidth. Looking at the Nginx logs only proves that there's a gateway timeout error related to the backend. I should check the application backend logs. Nothing there, no errors at all.
At this point, I start to blame the network and call the network infrastructure team. These guys work on an organisational level and potentially can see what I can't. After spending an hour investigating together, we see nothing. It's already Sunday evening, and I'm almost hopeless.
I decide to take a break and go for a walk. When I'm back, I try to ssh to a VM again. Suddenly, I notice a few seconds of delay before I can type my commands into a terminal. "It can't be DNS", I say to myself. To prove it, I ping a public domain from our network. Again, a few seconds of delay and the network packets are flying without a hitch. "If DNS was down, the infrastructure team would notice.", I continue to reason. Before escalating the situation further to upper management, I choose to check the DNS configuration on the backend virtual machines.
The /etc/resolv.conf is a DNS resolver configuration file. It contains records in the following format:
nameserver [ip]
nameserver [ip]In my developer's mind, a Linux machine receives these records at boot time and caches them. This file is then queried to resolve domains. What could possibly go wrong? Well, I ask the infrastructure team about the IP addresses I see in /etc/resolv.conf and get a surprising answer: "The IP addresses are DNS load balancers and the first one in the list is currently down". Hearing this, I begin to understand why the ssh and initial ping delays are happening. The first DNS load balancer is queried, but because it's down, it doesn't respond, and the resolution continues with the second IP address.
I remove the first nameserver from /etc/resolv.conf and drop the DNS cache on each of the VMs. After a few seconds, the 504 error and the gateway timeout disappear. In the morning, we'll discuss the incident with the infrastructure team and senior management. Fun week ahead.
It's not DNS
There's no way it's DNS
It was DNS